
Talk:Principal component analysis
| This It is of interest to the following WikiProjects: | |||||||||||||||||||||
| |||||||||||||||||||||


| The contents of the Non-linear iterative partial least squares page were merged into Principal component analysis on 6 May 2016. For the contribution history and old versions of the redirected page, please see its history; for the discussion at that location, see its talk page. |
|
This page has archives. Sections older than 365 days may be automatically archived by Lowercase sigmabot III when more than 10 sections are present. |
Dividing each attribute by its standard deviation changes principle components
[edit]This is/was suggested as a pre-processing step in the third paragraph, but it may change the directions of the principle components. Consider vectors [1,2] and [-1,-2]. The standard deviation across the values in the first coordinate is 1, and across the second is 2. Dividing, we get [1,1],[-1,-1], which will have a different set of principle components. Does this not defeat the purpose? AP295 (talk) 22:00, 26 March 2020 (UTC)
- Centering the data is an essential step in PCA, so that could be mentioned in the intro if someone feels it must. On the other hand, dividing each variable by its standard deviation may give you different principle components, the first of which may not preserve as much variance of the original data. I've searched around a bit, and it looks like the practice of using a correlation matrix isn't entirely uncommon, but it will not give you the same results with respect to your original data. If anyone has a good source on this, please let me know. The preceding sentence already describes the algorithm as an eigendecomposition or SVD of the covariance or correlation matrix, which are not affected by the variable means anyway, so the sentence was at least redundant. I propose re-writing that sentence as well to make it clear that using the correlation matrix may not yield the same results.AP295 (talk) 12:32, 27 March 2020 (UTC)
- This is original research. It is "principal" not "principle". And of course it can be done with normalized vectors in which case it has the covariance. If you revert I will bring it to ANI.Limit-theorem (talk) 19:29, 27 March 2020 (UTC)
- It is not original research. Do you agree that the first principal component should maximize the variance of the projected data points? PCA is defined as an optimization problem, and if instead of using the covariance matrix, you use the correlation matrix, the transformation you get may not be an optimal solution to this objective. See "Pattern Recognition and Machine Learning" by Bishop. AP295 (talk) 21:15, 27 March 2020 (UTC)
- @AP295: I think what Limit-theorem is talking about is that the sources that you are adding may be primary sources. We have a policy against that. You need to find an appropriate secondary reliable source (such as a journal article or a news article) that supports your addition, unfortunately, that is not what you have been doing. Instead, your edit seems to be backed by "that is the truth". Read this essay for an understanding of what that means. I have reverted your edit again, reinstating your edit constitutes edit warring. I do not want an admin to block you, but it is important that you comply with Wikipedia's content policies when you are editing. Thank you. Aasim 21:40, 27 March 2020 (UTC)
- @Awesome Aasim we clearly use both techniques and the page mentions it. Reported very disuptive editing, 3RR, with original research on WP:AN.Limit-theorem (talk) 21:43, 27 March 2020 (UTC)
- @Limit-theorem Who's "we"? Please re-consider my point. Are there any software packages that compute PCA using the correlation matrix instead of the covariance matrix? AP295 (talk)
- @Awesome Aasim I'm not sure I understand what you mean. I didn't add any content or cite any new sources in the article. I only removed something that was inconsistent with the usual definition of PCA.AP295 (talk) 21:56, 27 March 2020 (UTC)
- Wolfram's Mathematica does both covariance and correlation, and any book on Z scores used in finance and risk management. Limit-theorem (talk) 22:33, 27 March 2020 (UTC)
- @Limit-theorem Whether you apply PCA to z-scores or any other sort of data has nothing to do with PCA itself. At least make clear the distinction between necessary steps of the algorithm, like mean subtraction, and the sort of data you're using it on. Again, using the correlation matrix may not yield a solution to the maximum-variance/minimum-projection-error objective with respect to the original data. — Preceding unsigned comment added by AP295 (talk • contribs) 22:49, 27 March 2020 (UTC)
- I give up. It did not hit you that some methods use normalized variance "– and, possibly, normalizing each variable's variance to make it equal to 1; see Z-scores.[4]". The text does not deny that other nonnormalized methods exist, in ML or other. You are bordering on vandalism and will end up being blocked if you continue violating encyclopedic standards.Limit-theorem (talk) 22:55, 27 March 2020 (UTC)
- @Limit-theorem I understand what you mean, but using the correlation matrix changes the algorithm in a fundamental way, and I think this distinction should at least be made clear to the reader who might not understand the difference otherwise. AP295 (talk) 23:12, 27 March 2020 (UTC)
- It does not change anything methodologically since you are dealing with normalized vectors and derive their attributes. People can retranslate from the normalized vector to the raw one. Limit-theorem (talk) 11:49, 28 March 2020 (UTC)
- @Limit-theorem Please see my summary below. It seems we got off on the wrong foot. I'm not claiming that using PCA on standardized data is unsound or methodologically incorrect. AP295 (talk) 12:28, 28 March 2020 (UTC)
- It does not change anything methodologically since you are dealing with normalized vectors and derive their attributes. People can retranslate from the normalized vector to the raw one. Limit-theorem (talk) 11:49, 28 March 2020 (UTC)
- @Limit-theorem I understand what you mean, but using the correlation matrix changes the algorithm in a fundamental way, and I think this distinction should at least be made clear to the reader who might not understand the difference otherwise. AP295 (talk) 23:12, 27 March 2020 (UTC)
- I give up. It did not hit you that some methods use normalized variance "– and, possibly, normalizing each variable's variance to make it equal to 1; see Z-scores.[4]". The text does not deny that other nonnormalized methods exist, in ML or other. You are bordering on vandalism and will end up being blocked if you continue violating encyclopedic standards.Limit-theorem (talk) 22:55, 27 March 2020 (UTC)
- @Limit-theorem Whether you apply PCA to z-scores or any other sort of data has nothing to do with PCA itself. At least make clear the distinction between necessary steps of the algorithm, like mean subtraction, and the sort of data you're using it on. Again, using the correlation matrix may not yield a solution to the maximum-variance/minimum-projection-error objective with respect to the original data. — Preceding unsigned comment added by AP295 (talk • contribs) 22:49, 27 March 2020 (UTC)
- Wolfram's Mathematica does both covariance and correlation, and any book on Z scores used in finance and risk management. Limit-theorem (talk) 22:33, 27 March 2020 (UTC)
- @Awesome Aasim we clearly use both techniques and the page mentions it. Reported very disuptive editing, 3RR, with original research on WP:AN.Limit-theorem (talk) 21:43, 27 March 2020 (UTC)
- @AP295: I think what Limit-theorem is talking about is that the sources that you are adding may be primary sources. We have a policy against that. You need to find an appropriate secondary reliable source (such as a journal article or a news article) that supports your addition, unfortunately, that is not what you have been doing. Instead, your edit seems to be backed by "that is the truth". Read this essay for an understanding of what that means. I have reverted your edit again, reinstating your edit constitutes edit warring. I do not want an admin to block you, but it is important that you comply with Wikipedia's content policies when you are editing. Thank you. Aasim 21:40, 27 March 2020 (UTC)
- It is not original research. Do you agree that the first principal component should maximize the variance of the projected data points? PCA is defined as an optimization problem, and if instead of using the covariance matrix, you use the correlation matrix, the transformation you get may not be an optimal solution to this objective. See "Pattern Recognition and Machine Learning" by Bishop. AP295 (talk) 21:15, 27 March 2020 (UTC)
- This is original research. It is "principal" not "principle". And of course it can be done with normalized vectors in which case it has the covariance. If you revert I will bring it to ANI.Limit-theorem (talk) 19:29, 27 March 2020 (UTC)
I'd like to summarize my point and make a few things clear, please correct me if I'm mistaken about any of these points. Computing PCA using a correlation matrix instead of a covariance matrix will give you the same set of principal components that you'd get by standardizing your data and then applying the usual form of PCA. Rather than a "different method" of PCA, this could be viewed as applying PCA to a specific sort of data or as a pre-processing step unrelated to PCA itself (as opposed to mean-subtraction, which is a necessary step if you want to compute the covariance matrix using a matrix product). My concern is that the intro does not make this distinction clear. PCA is formulated as an optimization problem and using the correlation matrix may not yield the same solution to the maximum-variance/minimum-projection-error objective with respect to an arbitrary collection of data. Conflating the mathematical definition of PCA with a specific use makes the intro less clear. AP295 (talk) 12:20, 28 March 2020 (UTC)
- You are now doing WP:OR. Wikipedia is not about this, but about reflecting the professional literature. If you disagree with the literature, please publish and it will make its way to WP. Limit-theorem (talk) 12:49, 28 March 2020 (UTC)
- @Limit-theorem This is not original research. Two sections above this one, another user remarked that the intro should be re-written and the problem stated mathematically, and I agree with them. Without a precise definition of PCA to work from, we're not getting anywhere. AP295 (talk) 13:01, 28 March 2020 (UTC)
- I made sure it says that there are two methods, unambiguously. Limit-theorem (talk) 21:33, 28 March 2020 (UTC)
- @Limit-theorem This is not original research. Two sections above this one, another user remarked that the intro should be re-written and the problem stated mathematically, and I agree with them. Without a precise definition of PCA to work from, we're not getting anywhere. AP295 (talk) 13:01, 28 March 2020 (UTC)
That's a bit better, but I still think the intro needs work. I'll leave it alone for now, but you may find this code interesting:
import numpy as np
for i in range(5):
points = np.random.randn(3,1000)*np.array([[1],[10],[50]])
corr_mat = np.corrcoef(points)
cov_mat = np.cov(points)
evl_corr,evc_corr = np.linalg.eig(corr_mat)
evl_cov,evc_cov = np.linalg.eig(cov_mat)
print(np.round(evc_corr[:,np.argmax(evl_corr)],3), np.round(evc_cov[:,np.argmax(evl_cov)],3))
The variance in the third coordinate is very high compared to the others, so for the first principal component, you'd want a vector that lies close to or on that axis. However, because the correlation between different variables will be very small, the correlation matrix will be close to the identity matrix, where the "first" eigenvector is very sensitive to small differences. So the results will likely be different, and using the correlation matrix, they might also differ substantially between each run even though you have large samples of the same distribution, whereas the first PC you get from eigendecomposition of the covariance matrix will be fairly consistent. Again, I'm not at all claiming that PCA can't or shouldn't be applied to z-scores. Just that in this case, using a correlation matrix might not give someone the results they expect.
This condition was described by Karl Pearson himself: "This sphericity of distribution of points in space involves the vanishing of all the correlations between the variables and the equality of all their standard-deviations", in the original 1901 paper. AP295 (talk) 23:32, 29 March 2020 (UTC)
One more comment: Compare the first sentence of this article with how Pearson introduced PCA:
Wikipedia: Principal component analysis (PCA) is a statistical procedure that uses an orthogonal transformation to convert a set of observations of possibly correlated variables into a set of values of linearly uncorrelated variables called principal components.
Pearson: In many physical, statistical, and biological investigations it is desirable to represent a system of points in plane, three, or higher dimensioned space by the "best-fitting" straight line or plane.
In my opinion, the latter is a much clearer way to motivate the problem and convey its geometric intuition. AP295 (talk) 15:03, 30 March 2020 (UTC)
Maybe something like this: "Given a set of points in two, three, or higher dimensional space, a "best fitting" line can be defined as one that minimizes the average squared distance from a point to the line. The next best-fitting line can be similarly chosen from directions perpendicular to the first. Repeating this process yields an orthogonal basis in which individual dimensions of the data are uncorrelated." AP295 (talk) 14:34, 3 April 2020 (UTC)
I'd like to replace the first paragraph with: Given a collection of points in two, three, or higher dimensional space, a "best fitting" line can be defined as one that minimizes the average squared distance from a point to the line. The next best-fitting line can be similarly chosen from directions perpendicular to the first. Repeating this process yields an orthogonal basis in which different individual dimensions of the data are uncorrelated. These basis vectors are called Principal Components, and several related procedures Principal component analysis (PCA). I think it reads much more clearly than the current paragraph and describes PCA as the solution to a specific objective rather than a "statistical procedure", without being any less precise.
Any suggestions/objections? AP295 (talk) 14:29, 4 April 2020 (UTC)
- You are right! The Pearson's definition of Principal Components as the best approximation of the data cloud with minimisation of MSE (Mean squared error) is much more seminal that the definition of this article. Of course, minimisation of MSE is equivalent to maximisation of the variance of projection (a simple consequence of the Pythagorean theorem), but the approximation approach is much clearer and allows multiple nonlinear generalisations. BTW, the history of the "variance" reformulation of the original PCA could be interesting: who and what for destroyed the Pearson's approach and created this viral "variance" definition? Concerning your definition: It is correct, but the iterative algorithm of selection of Principal Components should be, perhaps, a consequence of the basic definition: the best approximation of data by k-dimensional linear manifolds (if we follow the original approach). For the centred data set, these k-dimensional linear manifolds form a complete flag of subspaces. Its orthogonal basis is called the principal components basis. ...Agor153 (talk) 12:10, 5 April 2020 (UTC)
- Thanks for your comment! My reference on the topic (Bishop) shows how the solution can be derived in each way, from maximum-variance and from minimum MSE projection-distance. Deriving a solution from the maximum variance objective seems a little bit simpler, but I think stating the objective geometrically, as a line or plane that minimizes squared distances, grounds the problem in terms anyone can understand. It's true that PCA is usually not computed in an explicitly iterative fashion like that (as far as I'm aware), but it's the most precise and accessible explanation I can come up with using so many words. The first k principal components form a basis for the best-fitting k-dimensional subspace, but an orthogonal basis for the best-fitting k-dimensional subspace doesn't necessarily comprise the first k principle components (correct me if I'm mistaken on this). And iteratively constructing/defining a basis should be familiar ground for anyone who has taken a course on linear algebra. Thanks again for your comments. I'm not a mathematician so second opinions are welcome. I'll wait a bit longer before editing the article. AP295 (talk) 13:48, 5 April 2020 (UTC)
- Fine. The only comment I have is: the orthonormal basis of a complete flag of subspaces is practically unique: the first vector belongs to the 1D subspace from the flag, the second vector is in its orthogonal complement in the 2D subspace from the flag, etc. The only uncertainty is in the signs - each vector can be multiplied by -1. Therefore, if we have the k-dimensional planes of the best approximation then the basis we speak about is uniquely defined (up to multiplications of some vectors by -1).Agor153 (talk) 13:58, 5 April 2020 (UTC)
- Thanks again. I replaced the opening paragraph but the article is still in a rough state. It reads more like a rough literature survey than an encyclopedic entry. Many things are repeated in different sections, and the article is littered with stray observations. AP295 (talk) 12:24, 7 April 2020 (UTC)
- Fine. The only comment I have is: the orthonormal basis of a complete flag of subspaces is practically unique: the first vector belongs to the 1D subspace from the flag, the second vector is in its orthogonal complement in the 2D subspace from the flag, etc. The only uncertainty is in the signs - each vector can be multiplied by -1. Therefore, if we have the k-dimensional planes of the best approximation then the basis we speak about is uniquely defined (up to multiplications of some vectors by -1).Agor153 (talk) 13:58, 5 April 2020 (UTC)
- Thanks for your comment! My reference on the topic (Bishop) shows how the solution can be derived in each way, from maximum-variance and from minimum MSE projection-distance. Deriving a solution from the maximum variance objective seems a little bit simpler, but I think stating the objective geometrically, as a line or plane that minimizes squared distances, grounds the problem in terms anyone can understand. It's true that PCA is usually not computed in an explicitly iterative fashion like that (as far as I'm aware), but it's the most precise and accessible explanation I can come up with using so many words. The first k principal components form a basis for the best-fitting k-dimensional subspace, but an orthogonal basis for the best-fitting k-dimensional subspace doesn't necessarily comprise the first k principle components (correct me if I'm mistaken on this). And iteratively constructing/defining a basis should be familiar ground for anyone who has taken a course on linear algebra. Thanks again for your comments. I'm not a mathematician so second opinions are welcome. I'll wait a bit longer before editing the article. AP295 (talk) 13:48, 5 April 2020 (UTC)
@Limit-theorem @Polybios23 FYI, the only reason I can think of to use a correlation matrix instead of computing the z-scores beforehand is to save a few division ops. If you have m data points with dimension n, then computing the z-scores would require m*n divisions, but after computing the covariance matrix, dividing out their standard deviations to get the correlation matrix would take O(n*n) ops. Since it's often the case that n<<m, this could be more efficient. As far as I know, Mathematica is closed source so we don't actually know what its PCA function does with that argument. It might just compute the z-scores and then use SVD. I'm curious why they do this, so if anyone knows, feel free to comment. Anyway, someone re-formatted the second paragraph but I still think it's misleading. Using the correlation matrix is not an equivalent formulation and that should be made clear. Again, I think that specific applications of PCA (e.g. to z-scores) and their specific pre-processing steps should not be conflated with the algorithm itself. Something to the effect of "The principal components are the eigenvectors of the covariance matrix obtained from the data, or equivalently the singular vectors from SVD of the data matrix." might be clearer and more appropriate for the intro. AP295 (talk) 15:49, 24 April 2020 (UTC)
See the section above #The_z-score_bit_is_messed_up where I note this topic has long been horribly messed up. It should be fixed, not removed, since normalizing by variance is indeed a very common part of PCA. Yes, it affects the components – it makes them independent of the measurement units, for example – and yes if you think of it as pre-process before PCA than you can keep your concept of PCA more pure. But omitting it or denying it is not helpful. I'm not familiar with covariance vs correlation as the way to explain this option, but if that's what sources do, it's fine for us to do so. I'd rather see the difference integrated as a small optional difference though. Dicklyon (talk) 19:15, 23 August 2020 (UTC)
Entry paragraph
[edit]Hello, the first sentence of the article was more about "how" than "what", so I created another one concerning "what" PCA is. We should further consider postponing the "how" discussion in my opinion; one does not need to know how to do something until s/he knows what it is and why s/he should use it. "Why" could follow "what", e.g. the sentence beginning with "PCA is mostly used as a tool..." could be the second sentence. What do you think? --Gufosowa (talk) 08:28, 24 July 2020 (UTC)
- @Gufosowa PCA is most easily understood as successively fitting lines to a set of points in space. Why start it off with "In statistics,"? It's not exclusively a statistical technique, and you don't always use the principal components for dimensionality reduction either. The article is in serious need of repair. Its unnecessarily long and obscures what is otherwise a very simple and elegant concept with jargon and a lack of continuity. If you want to repair it, the intro (and every other section) could use some work, but I think the opening paragraph was just fine the way it was. It was similar to how Pearson introduced PCA and I think he put it best. AP295 (talk) 15:24, 3 August 2020 (UTC)
- @AP295: you have not answered my main discussion point. If you have any issues with the definition sentence you can modify it. If you think that it doesn't only belong to statistics, then you can add anything else that it belongs to. There was not a mention of dimensionality reduction anyway.
- "...fitting lines to a set of points in space" is "linear regression". The current entry paragraph talks about all other things which have their own pages in Wikipedia, until defining PCA at the very end. This does not fit the Wikipedia standard at all. Here are some examples of good entry paragraphs: 1 2 3
- Wikipedia is an encyclopedia, it is not a textbook. So the discussion of "what" should precede the discussion of "how". Do you have any objections to that? --Gufosowa (talk) 17:12, 3 August 2020 (UTC)
- @Gufosowa: It is fallacious to think that the reason linear regression is called linear regression is that it involves fitting lines. Polynomial regression, for example, is an instance of linear regression, so called for good reasons. Michael Hardy (talk) 04:16, 1 September 2020 (UTC)
- @Gufosowa The definition I gavein the intro is equivalent to the maximum variance formulation, and not equivalent to linear regression. You cannot fit a vertical line with linear regression, for example. I believe it will be clearest to other English speakers the way I've written it, so I do object to any changes . Defining "principal component analysis" requires defining what a "principal component" is, and I've condensed that into as short and accessible an explanation as I could. AP295 (talk) 17:22, 3 August 2020 (UTC)
- @Gufosowa Again, the rest of the article does need a lot of work, so I don't mind at all if you want to improve other sections. Even the rest of the intro is a bit misleading and will need to be rewritten at some point. AP295 (talk) 17:27, 3 August 2020 (UTC)
- @AP295: If it is equal to maximum variance, then you can simply say "maximum variance" in the definition. We don't need to explain every fundamental concept. If someone does not know what variance is, they can follow the link to the variance page. Otherwise we would need to recite everything from Pythagoras. This article is about PCA, and PCA only.
- I do not like the current entry paragraph because of these two reasons: 1) It discusses "how" before "what" 2) It delays "PCA" to discuss other things that have their own pages.
- Hence, I created a sentence that talks about "what" and gives "PCA" right away (Please compare to link 1 link 2 link 3):
- "In statistics, principal component analysis (PCA) is a method to project data in a higher dimensional space into a lower dimensional space by maximizing the variance of each dimension."
- It is open for modifications. If you have any oppositions to 1) and 2) please share. --Gufosowa (talk) 17:46, 3 August 2020 (UTC)
- @Gufosowa It doesn't start with the "how", it starts with a definition of "best fitting line", which is the objective that PCA optimizes. It is immediately clear to most readers what that means. Yes, PCA maximizes the variance of the projected data, but why lead with that? I don't think it's unreasonable to choose the simpler of two equivalent definitions to state in the intro. Nothing is "delayed" by this introduction, I think the reader can bear with it for the whole four sentences before at long last they come to the definition of "Principal component". If you're concerned about brevity, the rest of the article could use a lot of work in that regard. AP295 (talk) 17:59, 3 August 2020 (UTC)
- @Gufosowa I'll add that I think readability is far more important than rigid stylistic convention. Most people use Wikipedia as a learning tool. You don't have to shoehorn the entire definition into the first sentence. AP295 (talk) 18:21, 3 August 2020 (UTC)
- @AP295: Starting with the definition of "best fitting line" is what I mean by delaying.
- Starting with "what" is not only for the stylistic convention, but also for a more healthy approach to a topic. As I mentioned above "one does not need to know how to do something until s/he knows what it is and why s/he should use it". Anyway, our positions are clear and I started to repeat myself. Let's hear other Wikipedists' opinions, too. --Gufosowa (talk) 19:49, 3 August 2020 (UTC)
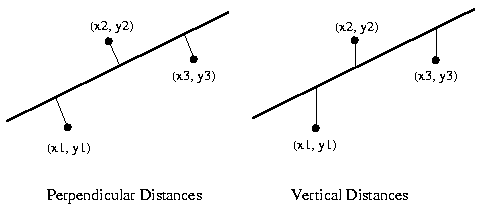
- @Gufosowa It is absolutely necessary to define "best fitting line". Linear regression minimizes squared vertical distances between the points and the line i.e. (f(x)-y)^2. The first principle component minimizes squared (orthogonal) distances. Perhaps a graphic would help: https://services.math.duke.edu/education/modules2/materials/test/test/errors.gif Maybe I'll make something similar for this article. AP295 (talk) 20:14, 3 August 2020 (UTC)
Dear Agor153, Cowlinator, Dicklyon, I pinged you as you are active users who wrote to this talk page previously. Could you please give an input to resolve this discussion? It is stuck for more than a week. Thank you. --Gufosowa (talk) 08:50, 12 August 2020 (UTC)
- Yes, I agree with you that the current description in the lead is more a process than a definition. I'd saying something like how it was before AP295 changed it in this edit was better, though still not great. Let's go back and craft a compromise. Dicklyon (talk) 20:46, 12 August 2020 (UTC)
- The intro in the edit you linked describes PCA as a "statistical procedure" (whatever that is) and is practically a circular definition, so I really can't imagine why you think the current intro is more "procedural" in nature than the old one. That's exactly the sort of description I intended to avoid by first stating the objective function, then defining principal components as a solution to that objective. If you want to change it, I insist you define PCA in terms of the least-squares objective, and define "principal component" in the simplest possible terms as a solution to that objective. Pearson described it geometrically in terms of the objective it optimizes, and I feel that this is much clearer than using jargon like "statistical procedure". I also insist that it not start with the phrase "In statistics," AP295 (talk) 22:16, 12 August 2020 (UTC)
- I'm not saying it was a great lead, which is why I suggested working on a compromise. It's not clear to me why you object to "In statistics" for starters. Is there a better way to characterize the field within which this concept is meaningful? Wasn't Pearson a statistician? And I always thought of PCA as maximizing the variance captured, as opposed to minimizing the residual, so didn't think of it as a "least squares" thing, though I agree that's one approach. The basic idea of fitting a line to data seems imperfect, though, as least squares fitting usually starts with an independent variable, which we don't have in this case. Anyway, there are various ways to go about this. I suggest each of you find some sources to compare how they go about it. Dicklyon (talk) 00:27, 13 August 2020 (UTC)
- Pearson was a statistician, and yet he still chose to introduce the concept geometrically. The least-squares approach highlights the difference between PCA and linear regression, and nicely ties it in with linear algebra while remaining (relatively) accessible to the average undergrad. Ideally this article would introduce the problem in terms of the objective (and thus defining "principal component"), solve for the first PC (thus showing it's an eigenvector), and then move on to alternative derivations, efficient calculation of the principal components via SVD/eigendecomposition, applications, etc. I object to the article starting with the phrase "In statistics", because statistics is but one area where PCA is applied (perhaps we can say how it's applied in the "applications" section), and I feel it's a slight psychological deterrent to the average reader. AP295 (talk) 18:22, 14 August 2020 (UTC)
- How about "In data analysis" then? Dicklyon (talk) 06:44, 15 August 2020 (UTC)
- Unless there's another field in which "principal component analysis" has an entirely different meaning, I don't see the need to so distinguish PCA in the first sentence of this article. Applications can be addressed in the "applications" section. AP295 (talk) 16:49, 15 August 2020 (UTC)
- P.S. I would not be opposed to a very clear and well-organized derivation from maximum variance if we can replace the whole intro (and maybe clean up some of the main article) instead of just the first paragraph. The whole article needs work and it's not my intent to be an obstacle here. I'd rather people not make quick and careless edits to the first paragraph though, as I've thought very carefully about how it should read. AP295 (talk) 01:33, 16 August 2020 (UTC)
- Thank you for invitation to this discussion. I can say the both positions are correct but (1) I prefer Pearson's definition principal components through best fit. Nevertheless, Pearson used "lines and planes of best fit". This means that the plane of k first principal components is defined as a k-dimensional plane of best fit. The iterative process used now in the first paragraph is a simple theorem, a consequence of the definition (the mean point belongs to the line of the first component, the line belongs to the plane, etc.). There is one unpleasant incorrectness now: the iterative procedure is not yet formally defined if the eigenspectrum is degenerated (of course, the correction is obvious but forces us to discuss minor technical issues when we must discuss ideas. The "object-oriented" intro ("what ") seems to be better than the procedure-oriented one. Thus, if my opinion matters> I prefer Pearson's definition through data approximation (especially because it allows immediate non-linear generalisations, while the "variance approach" does not). Nevertheless, this definition is better to introduce correctly, as Pearson did, lines and planes of best fit (this is 'what', not 'how'), and then the iterative procedure can be presented as the simple corollary (with all proper formulations for degenerated spectra).-Agor153 (talk) 20:19, 16 August 2020 (UTC)
- I'm not sure what you mean. You can always find a "best-fitting" line. There may be more than one direction to choose from but it's the same up to the order they're selected. (edit: If there aren't enough linearly independent eigenvectors then any orthogonal basis for the remaining subspace can be taken. This doesn't contradict the definition in the first paragraph, although you're correct if you meant that there may not be a unique solution. This seems like a very minor issue that can be addressed elsewhere.) Does WP have any official guidelines on how much technical competence we should expect from the reader? At least, I think the intro should be relatively gentle, and that's why I wrote up the construction that's currently in the first paragraph. The intro is not the place to slam the reader with technical jargon, unnecessary comments, stray observations, etc. We do not want to deter the reader. It should be as simple as reasonably possible. AP295 (talk) 18:50, 17 August 2020 (UTC)
- Thank you for invitation to this discussion. I can say the both positions are correct but (1) I prefer Pearson's definition principal components through best fit. Nevertheless, Pearson used "lines and planes of best fit". This means that the plane of k first principal components is defined as a k-dimensional plane of best fit. The iterative process used now in the first paragraph is a simple theorem, a consequence of the definition (the mean point belongs to the line of the first component, the line belongs to the plane, etc.). There is one unpleasant incorrectness now: the iterative procedure is not yet formally defined if the eigenspectrum is degenerated (of course, the correction is obvious but forces us to discuss minor technical issues when we must discuss ideas. The "object-oriented" intro ("what ") seems to be better than the procedure-oriented one. Thus, if my opinion matters> I prefer Pearson's definition through data approximation (especially because it allows immediate non-linear generalisations, while the "variance approach" does not). Nevertheless, this definition is better to introduce correctly, as Pearson did, lines and planes of best fit (this is 'what', not 'how'), and then the iterative procedure can be presented as the simple corollary (with all proper formulations for degenerated spectra).-Agor153 (talk) 20:19, 16 August 2020 (UTC)
- How about "In data analysis" then? Dicklyon (talk) 06:44, 15 August 2020 (UTC)
- Pearson was a statistician, and yet he still chose to introduce the concept geometrically. The least-squares approach highlights the difference between PCA and linear regression, and nicely ties it in with linear algebra while remaining (relatively) accessible to the average undergrad. Ideally this article would introduce the problem in terms of the objective (and thus defining "principal component"), solve for the first PC (thus showing it's an eigenvector), and then move on to alternative derivations, efficient calculation of the principal components via SVD/eigendecomposition, applications, etc. I object to the article starting with the phrase "In statistics", because statistics is but one area where PCA is applied (perhaps we can say how it's applied in the "applications" section), and I feel it's a slight psychological deterrent to the average reader. AP295 (talk) 18:22, 14 August 2020 (UTC)
- I'm not saying it was a great lead, which is why I suggested working on a compromise. It's not clear to me why you object to "In statistics" for starters. Is there a better way to characterize the field within which this concept is meaningful? Wasn't Pearson a statistician? And I always thought of PCA as maximizing the variance captured, as opposed to minimizing the residual, so didn't think of it as a "least squares" thing, though I agree that's one approach. The basic idea of fitting a line to data seems imperfect, though, as least squares fitting usually starts with an independent variable, which we don't have in this case. Anyway, there are various ways to go about this. I suggest each of you find some sources to compare how they go about it. Dicklyon (talk) 00:27, 13 August 2020 (UTC)
- The intro in the edit you linked describes PCA as a "statistical procedure" (whatever that is) and is practically a circular definition, so I really can't imagine why you think the current intro is more "procedural" in nature than the old one. That's exactly the sort of description I intended to avoid by first stating the objective function, then defining principal components as a solution to that objective. If you want to change it, I insist you define PCA in terms of the least-squares objective, and define "principal component" in the simplest possible terms as a solution to that objective. Pearson described it geometrically in terms of the objective it optimizes, and I feel that this is much clearer than using jargon like "statistical procedure". I also insist that it not start with the phrase "In statistics," AP295 (talk) 22:16, 12 August 2020 (UTC)
- I edited the intro to include a definition based on the maximum variance objective, and I think it reads a bit more clearly. This and the first paragraph are really just recursive definitions of the principal components, so I don't consider them to be too "procedural" in nature. However, if anyone objects, please let me know why. I'd really like to delete the rest of the intro after the first couple paragraphs include a simple proof that the first PC is an eigenvector in its place, but I'll wait for comments. AP295 (talk) 17:03, 18 August 2020 (UTC)
- Some more edits. Hopefully this is a satisfactory compromise. It's starting to look like a good intro in my opinion. The terms "Principal Component" and PCA are clearly defined and both objectives are briefly covered. I don't think we need to be overly pedantic in the intro. Anyway, there's still a lot of repetition in the rest of the article that should be removed at some point. It seems like the article has been continually added to without much attempt at maintaining its continuity/readability. AP295 (talk) 14:30, 19 August 2020 (UTC)
- @Dicklyon To be honest, I don't think your edit reads as nicely. The phrase "directions (principal components) that align with most of the variation" is not as precise or succinct as either recursive definition. It is awkward to define PCA without first taking a couple sentences to define "principal components" and I don't think it does the reader any good to force this style. It would actually make a lot more sense to re-title the article "Principal Components" and have "PCA" redirect to the article, since the term "PCA" doesn't seem to have a single concrete definition. Please consider this idea. AP295 (talk) 18:25, 19 August 2020 (UTC)
- I'm not saying I got it to a great state, but I really think we need to lead with a definition, not a tutorial. And please avoid caplitalization of things that aren't proper names. Dicklyon (talk) 22:48, 19 August 2020 (UTC)
- @Dicklyon The article starts with a recursive definition of principal components. If you want to phrase it a bit more formally that's fine by me but it is a (reasonably) precise mathematical definition. AP295 (talk) 22:56, 19 August 2020 (UTC)
- @Dicklyon I made a few changes to the intro as they came to mind. It's really the same intro but with slightly better wording, and I hope you'll be convinced that this is a reasonable way to present the topic. Keep in mind that PCA can be defined completely without reference to any concepts from statistics at all. PCA is a change of basis that satisfies the recursive least-squares objective described in the first paragraph, and I feel that's by far the most natural way to introduce it. AP295 (talk) 03:07, 20 August 2020 (UTC)
- @Dicklyon The article starts with a recursive definition of principal components. If you want to phrase it a bit more formally that's fine by me but it is a (reasonably) precise mathematical definition. AP295 (talk) 22:56, 19 August 2020 (UTC)
- I'm not saying I got it to a great state, but I really think we need to lead with a definition, not a tutorial. And please avoid caplitalization of things that aren't proper names. Dicklyon (talk) 22:48, 19 August 2020 (UTC)
Arbitrary break
[edit]@Gufosowa @Dicklyon @Agor153 I invite you to read the current intro. I'll take a break from editing the article for now but I feel it's much, much clearer and more precise than the intro linked earlier in the talk page. PCA is not inherently a statistical concept per se, it's essentially just a change of basis that satisfies the objective(s) described in the intro. There's no point in forcing it all into one sentence because it won't be comprehensible by anyone who isn't already familiar with PCA. Please be careful if you edit it. We should aim to communicate, rather than merely document. AP295 (talk) 15:20, 20 August 2020 (UTC)
One final thought for today. On Wikipedia it is conventional that the article's topic should be defined/referenced in the first sentence or shortly thereafter. This is understandable; it would be very inconvenient to "delay" the definition any more than a few short sentences, and I've not done so here. However, readers visit an article to understand the topic of that article. Any material before you reference the topic/title is probably going to be read and carefully considered by the reader. In this sense, it is a good opportunity to communicate important ideas and concepts because it may command a great deal of the reader's attention. AP295 (talk) 16:07, 20 August 2020 (UTC)
- Thanks for your efforts on this, but I don't think it's important for the reader to study distance from a line before knowing that a principal component is a best-fit direction vector; so I've taken another cut at a normal lead starting with a definition that tries to be clear and neutral with respect to whether one prefers the max variance or min distance approach. Please see what you think, do try to improve it. Dicklyon (talk) 20:52, 21 August 2020 (UTC)
- I beg to differ. Both you and Gufosowa seem to think that I'm describing regression here. There is no dependent variable in PCA. The terms in the objective function are not residuals. Agor153, please help. AP295 (talk) 23:00, 21 August 2020 (UTC)
- That's not what I'm thinking. Residuals are what's left after subtracting off a model, regression or not. There was no mention of independent or dependent variables in the lead I wrote. You have reverted attempted improvements too many times now; please stop that. Dicklyon (talk) 04:16, 22 August 2020 (UTC)
- The terms errors and residuals have a specific meaning. The term "distances" is more appropriate for explaining PCA in a general context where your points may not be a statistical sample, and less likely to confuse someone who isn't a statistician. AP295 (talk) 17:27, 22 August 2020 (UTC)
- That's not what I'm thinking. Residuals are what's left after subtracting off a model, regression or not. There was no mention of independent or dependent variables in the lead I wrote. You have reverted attempted improvements too many times now; please stop that. Dicklyon (talk) 04:16, 22 August 2020 (UTC)
- I agree in Dicklyon's change. We do not have to establish all the background, we assume that the reader knows basic concepts like line, error, dimension, space etc. We already have a best fit line article in Wikipedia, we can simply link to it. If the reader does not understand it and find it important, they may follow the link. Hence, the following part is redundant:
Given a collection of points in two, three, or higher dimensional space, a "best fitting" line can be defined as one that minimizes the average squared distance from a point to the line. For a collection of points in and , a direction for the best-fitting line can be chosen from directions perpendicular to the first best-fitting lines
- It should be removed or postponed to the methodology sections. If AP295 is concerned that linear regression works numerically while PCA geometrically, we can add it as a keyword in the sentence. --Gufosowa (talk) 13:22, 22 August 2020 (UTC)
- Regression is a fundamentally different idea from PCA. I urge you to carefully consider that "redundant" sentence. If it is incorrect, then please explain my mistake. Otherwise I insist that it remain in the article's intro. AP295 (talk) 16:38, 22 August 2020 (UTC)
- PS I am trying to help you here. It's disappointing when a simple and elegant concept like PCA is obscured by jargon and careless editing. WP is a great resource and I use it all the time. I don't want anyone to come away from this article confused or with mistaken ideas about what PCA is. AP295 (talk) 16:52, 22 August 2020 (UTC)
- I don't say that it is incorrect, I say that it is redundant. It does not belong to the top of the PCA article. It has its own article already. If you have concerns, please try to fix it instead of reverting altogether. Thank you. --Gufosowa (talk) 17:46, 22 August 2020 (UTC)
- But it isn't. It's the base case of PCA's recursive definition. We define the first PC and then we define the ith PC using the first i-1 PCs. This is an extremely common pattern in both computer science and the construction of a basis in linear algebra e.g. the Gram–Schmidt process AP295 (talk) 18:41, 22 August 2020 (UTC)
- @Gufosowa @Dicklyon Since this doesn't seem to be going anywhere, I've made a topic on the dispute resolution noticeboard. — Preceding unsigned comment added by AP295 (talk • contribs)
- Thanks. And I've notified you of your 3RR limit at your talk page. It has actually gone somewhere, in that several of us think your approach is wrong and are trying to fix it. I agree with you that it can perhaps be more clear and precise and jargon free, but within the framework of a normal lead please; don't lead with a tutorial. Dicklyon (talk) 20:13, 22 August 2020 (UTC)
- I don't say that it is incorrect, I say that it is redundant. It does not belong to the top of the PCA article. It has its own article already. If you have concerns, please try to fix it instead of reverting altogether. Thank you. --Gufosowa (talk) 17:46, 22 August 2020 (UTC)
- I beg to differ. Both you and Gufosowa seem to think that I'm describing regression here. There is no dependent variable in PCA. The terms in the objective function are not residuals. Agor153, please help. AP295 (talk) 23:00, 21 August 2020 (UTC)




Re errors and residuals, residual is clearly more correct within those definitions, and is in common use, e.g. at Matlab's "PCA Residual" function; or this book that talks about the amount that is unexplained by the pc model—the residual on p.35, and on the next page they examine the sum of squares of the residuals. Dicklyon (talk) 20:26, 22 August 2020 (UTC)
- The term "residual" occurs in the context of statistics. We don't need to call it that here. Calling the objective "average squared distance" is entirely correct, more general in a mathematical sense, and much more likely to be understood by a casual reader. I don't know what you're thinking. In "Pattern Recognition and Machine Learning", Bishop calls it the "minimum error" formulation, but there's really no harm at all in just calling them distances. AP295 (talk) 20:36, 22 August 2020 (UTC)
- If you see a way to improve it without throwing out the basic normal lead style, please go ahead. But in discussing differences, it can also be very helpful to link sources that do it more like what you're proposing. It shouldn't be hard to converge on a good wording. It's not clear to me what you think the context is here that's broader than statistics. Dicklyon (talk) 21:24, 22 August 2020 (UTC)
- I've already explained the reasons I think we should use the term "distance" instead of errors or residuals. Let's wait until they open the discussion on the dispute resolution page so we aren't wasting our time. PCA is an uncomplicated concept that anyone can understand and a great example of how linear algebra can be applied to real-world problems. This article is a travesty, so I'm trying to improve its correctness and organization while minimizing the amount of background knowledge it requires from the reader. AP295 (talk) 21:57, 22 August 2020 (UTC)
- I do appreciate that you're trying to improve. Please explain why you think it's a travesty, after all the years of work by so many other editors. You might also consider responding to my questions, providing sources, etc., as a way to help move the discussion forward, rather than just insisting on your idiosyncratic approach to the lead. Re residuals vs distances, you've said The terms errors and residuals have a specific meaning. The term "distances" is more appropriate for explaining PCA in a general context where your points may not be a statistical sample, and less likely to confuse someone who isn't a statistician. I don't understand why you claim that "distances" is more appropriate, esp. in light of the sources I showed that have "residuals"; and I don't see how not being a statistician is relevant to how confusing any of these terms might be. I'm not a statistician, and it seems OK to me. Also not clear why you think points being a "statistical sample" is relevant; you can compute statistics on data no matter where they came from, no? Dicklyon (talk) 22:47, 22 August 2020 (UTC)
- The word "distances" is more appropriate because that is what they are. The concept of distance is defined in any metric space (edit: you'd need at least the structure of a normed vector space for PCA to make sense, but my point is that distance is a suitably general and well-understood term). The terms "residual" and "error" are often used in the context of regression, which is different from PCA. They are less general and less likely to be understood by the average reader. AP295 (talk) 00:58, 23 August 2020 (UTC)
- I do appreciate that you're trying to improve. Please explain why you think it's a travesty, after all the years of work by so many other editors. You might also consider responding to my questions, providing sources, etc., as a way to help move the discussion forward, rather than just insisting on your idiosyncratic approach to the lead. Re residuals vs distances, you've said The terms errors and residuals have a specific meaning. The term "distances" is more appropriate for explaining PCA in a general context where your points may not be a statistical sample, and less likely to confuse someone who isn't a statistician. I don't understand why you claim that "distances" is more appropriate, esp. in light of the sources I showed that have "residuals"; and I don't see how not being a statistician is relevant to how confusing any of these terms might be. I'm not a statistician, and it seems OK to me. Also not clear why you think points being a "statistical sample" is relevant; you can compute statistics on data no matter where they came from, no? Dicklyon (talk) 22:47, 22 August 2020 (UTC)
- I've already explained the reasons I think we should use the term "distance" instead of errors or residuals. Let's wait until they open the discussion on the dispute resolution page so we aren't wasting our time. PCA is an uncomplicated concept that anyone can understand and a great example of how linear algebra can be applied to real-world problems. This article is a travesty, so I'm trying to improve its correctness and organization while minimizing the amount of background knowledge it requires from the reader. AP295 (talk) 21:57, 22 August 2020 (UTC)
- If you see a way to improve it without throwing out the basic normal lead style, please go ahead. But in discussing differences, it can also be very helpful to link sources that do it more like what you're proposing. It shouldn't be hard to converge on a good wording. It's not clear to me what you think the context is here that's broader than statistics. Dicklyon (talk) 21:24, 22 August 2020 (UTC)
@Gufosowa: AP295 forgot to ping us to the WP:DRN discussion he started about us. Please see at Wikipedia:Dispute_resolution_noticeboard#Principal_component_analysis and enter your summary of the dispute if you like. I just did mine. Dicklyon (talk) 22:56, 22 August 2020 (UTC)
@Dicklyon The first PC is a vector with the same direction as a line that best fits the data. This line may not be a vector itself, meaning the line that best fits the data may not pass through the origin. This technicality is not a problem if you say "the direction of a line". Incidentally, this is why the data must be centered if you compute the covariance matrix using an outer product (Gramian matrix). AP295 (talk) 18:02, 23 August 2020 (UTC)
- Yes, I understand that. Is there a rewording that you suggest then? Dicklyon (talk) 20:16, 23 August 2020 (UTC)
- If you say so. I already made the change. AP295 (talk) 20:18, 23 August 2020 (UTC)
- This sentence OK, but they you have "Each subsequent principal component is a direction of a line that minimizes the sum of squared distances and is orthogonal to the first principal components." where I had "Each subsequent principal component is a direction orthogonal to the first that best fits the residual." It's not clear to me what your distances refer to if you're not operating on residuals from the previous. Does this work for distances of original data points (perhaps it does, though it's not obvious to me, not how I was thinking of it). Dicklyon (talk) 23:08, 23 August 2020 (UTC)
- Finding the ith principal component could be viewed as a constrained optimization problem (and in fact you can use Lagrange multipliers to show that it's an eigenvector. Bishop does this in "Pattern Recognition and Machine Learning"). You're trying to find a best-fitting line whose direction is orthogonal to the directions of the first i-1 best-fitting lines, with the base case i=1 being unconstrained*. We have to say "directions of the best fitting line" because we are only concerned with their directions. They don't have to pass through the origin, but it's their directions (usually taken as unit vectors) that form the basis of principal components. AP295 (talk) 03:48, 24 August 2020 (UTC)
- *Edit- Unconstrained in its direction. Bishop actually uses a normality constraint to enforce ||u||=1. Just didn't want that to be a point of confusion/contention. AP295 (talk) 04:31, 24 August 2020 (UTC)
- I'll put it another way. For the first principal component, one can take (the direction of) a line (say, defined in terms of a direction (||direction||=1) and translation in R^n as the set of points {c*direction+translation | c in R}) that best fits the data. For the ith, take (the direction of) a line that best fits the data, but only from among those lines whose direction is orthogonal to the direction of the first i-1 lines. AP295 (talk) 04:31, 24 August 2020 (UTC)
- You mean Bishop's section 12.1.2 on projection error minimization? I don't have access to my copy at work these days, but on Amazon I can see some of the relevant pages. Unfortunately not page 564 where he might support what you're saying. I'm not saying you're wrong, just that looking at the residuals makes so much more sense. Also note that he does the maximum variance formulation first. Dicklyon (talk) 05:03, 24 August 2020 (UTC)
- @Dicklyon The "residuals" (which usually refer to scalar values, but I suspect you're talking about the parts that don't lie in the subspace spanned by PCs up to i-1) from projecting onto the i-1 PCs are orthogonal to those i-1 PCs by definition. You can just fit the ith PC under the condition that it be orthogonal to the first i-1 PCs. This is a much more natural way of looking at it. AP295 (talk) 14:08, 24 August 2020 (UTC)
- I don't see it as more natural. Can you point out a source that does it that way? Does Bishop? Sorry, I can't see the relevant page. And yes of course residuals are vectors; how would they be scalars? Dicklyon (talk) 16:12, 24 August 2020 (UTC)
- Yes, Bishop does. If are our first i-1 principal components, then a vector v can be decomposed into Where vector R must be orthogonal to the subspace spanned by . If you restrict your selection of the ith principal component to only those unit vectors orthogonal to P's columns, then AP295 (talk) 16:31, 24 August 2020 (UTC)
- Good, that's a convincing demonstration that the ith direction applied to the residual R is the same as the ith direction applied to the original vector. But does he really suggest skipping the computation of R, as a practical matter? Wouldn't it be easier to compute R than to constrain the ith direction to be orthogonal to all those other directions? How do you do that exactly? Or is it just a gedanken thing? Dicklyon (talk) 00:12, 25 August 2020 (UTC)
- This is a recursive definition, and basically the same one Bishop uses. If you set it all up like Bishop does and set the vector of partial derivatives equal to zero, then you get that it's an eigenvector of the covariance matrix. So, they're computed with eigendecomposition or SVD, as I mentioned in Principal Component Analysis. I did make a small omission in that revision, to the maximum variance explanation. In that case it would be easiest to assume the data are mean-centered and talk only about directions, otherwise the variance has no maximum (a "line" can be translated to make the variance infinite even if we parameterize it as having a unit vector for direction). But it's otherwise correct as far as I know. In any case, the minimum-squared-distances presentation is cleaner. AP295 (talk) 01:07, 25 August 2020 (UTC)
- Anyway, if you see what I mean, I think we should start from this revision - Principal Component Analysis. We first define "best-fitting line", then define our objective as a series of "best-fitting" lines, then state the solution to that objective. This is the most sensible progression in my opinion, and we remind the reader of several important concepts along the way. AP295 (talk) 17:50, 25 August 2020 (UTC)
- That might be a good approach for an "Introduction" section; not for the lead. Dicklyon (talk) 21:17, 25 August 2020 (UTC)
- If the article were renamed "Principal Components" we would not have to hem and haw about what PCA means in the first sentence. We could take the intro in the revision I linked earlier and just put something like this in front of it: "The principal components of a collection of points in R^n are a sequence of n vectors where the ith element is the direction of a line that best fits the data and is orthogonal to the first i-1 elements" AP295 (talk) 22:01, 25 August 2020 (UTC)
- I didn't rename the article, but I made a few changes along those lines. AP295 (talk) 22:17, 25 August 2020 (UTC)
- That might be a good approach for an "Introduction" section; not for the lead. Dicklyon (talk) 21:17, 25 August 2020 (UTC)
- Good, that's a convincing demonstration that the ith direction applied to the residual R is the same as the ith direction applied to the original vector. But does he really suggest skipping the computation of R, as a practical matter? Wouldn't it be easier to compute R than to constrain the ith direction to be orthogonal to all those other directions? How do you do that exactly? Or is it just a gedanken thing? Dicklyon (talk) 00:12, 25 August 2020 (UTC)
- Yes, Bishop does. If are our first i-1 principal components, then a vector v can be decomposed into Where vector R must be orthogonal to the subspace spanned by . If you restrict your selection of the ith principal component to only those unit vectors orthogonal to P's columns, then AP295 (talk) 16:31, 24 August 2020 (UTC)
- I don't see it as more natural. Can you point out a source that does it that way? Does Bishop? Sorry, I can't see the relevant page. And yes of course residuals are vectors; how would they be scalars? Dicklyon (talk) 16:12, 24 August 2020 (UTC)
- I see my link to the change of basis page is gone from the intro, but think about about how a vector decomposes into a linear combination of basis vectors. This is a fundamental concept and I think everyone could do with a reminder. Please fix the intro if you understand what I'm saying. AP295 (talk) 15:04, 24 August 2020 (UTC)
- You could do some fixing instead of just complaining and reverting, no? Dicklyon (talk) 16:12, 24 August 2020 (UTC)
- I've been trying to fix this article since March.
- You could do some fixing instead of just complaining and reverting, no? Dicklyon (talk) 16:12, 24 August 2020 (UTC)
- @Dicklyon The "residuals" (which usually refer to scalar values, but I suspect you're talking about the parts that don't lie in the subspace spanned by PCs up to i-1) from projecting onto the i-1 PCs are orthogonal to those i-1 PCs by definition. You can just fit the ith PC under the condition that it be orthogonal to the first i-1 PCs. This is a much more natural way of looking at it. AP295 (talk) 14:08, 24 August 2020 (UTC)
- You mean Bishop's section 12.1.2 on projection error minimization? I don't have access to my copy at work these days, but on Amazon I can see some of the relevant pages. Unfortunately not page 564 where he might support what you're saying. I'm not saying you're wrong, just that looking at the residuals makes so much more sense. Also note that he does the maximum variance formulation first. Dicklyon (talk) 05:03, 24 August 2020 (UTC)
- This sentence OK, but they you have "Each subsequent principal component is a direction of a line that minimizes the sum of squared distances and is orthogonal to the first principal components." where I had "Each subsequent principal component is a direction orthogonal to the first that best fits the residual." It's not clear to me what your distances refer to if you're not operating on residuals from the previous. Does this work for distances of original data points (perhaps it does, though it's not obvious to me, not how I was thinking of it). Dicklyon (talk) 23:08, 23 August 2020 (UTC)
- If you say so. I already made the change. AP295 (talk) 20:18, 23 August 2020 (UTC)
![{\displaystyle P_{i-1}=[p_{1},p_{2},\dots ,p_{i-1}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ddc6601f21ded9853077bd096b6085a4d46b082d)



How's this? I think it reads pretty well and it's closer to the usual style. AP295 (talk) 22:27, 25 August 2020 (UTC)
- Better. I'd avoid the formal mathy "points in " in the lead sentence, especially since you then use the word "vector" for the same kind of object. See if you can simplify that to plain English; it doesn't need to start too formal or precise. Dicklyon (talk) 22:35, 25 August 2020 (UTC)
- "Points in R^n" is there to let the reader know that our sequence is of equal length as the dimension. — Preceding unsigned comment added by AP295 (talk • contribs) 00:01, 26 August 2020 (UTC)
- I took a stab at saying it in English. Sadly, the article uses dimension p, not n. Dicklyon (talk) 00:37, 26 August 2020 (UTC)
- That's fine then. Unless Gufosowa has an issue with it we can probably close the topic on the DRN. I will probably continue to edit the rest of the article when I have time though. AP295 (talk) 01:03, 26 August 2020 (UTC)
- Good idea. It still needs work on terminological and variable name consistency, and work on the Z thing per discussions above. Dicklyon (talk) 04:27, 26 August 2020 (UTC)
- It looks better, thank you for improving it. Let's close the DRN topic then. --Gufosowa (talk) 20:08, 26 August 2020 (UTC)
- Good idea. It still needs work on terminological and variable name consistency, and work on the Z thing per discussions above. Dicklyon (talk) 04:27, 26 August 2020 (UTC)
- That's fine then. Unless Gufosowa has an issue with it we can probably close the topic on the DRN. I will probably continue to edit the rest of the article when I have time though. AP295 (talk) 01:03, 26 August 2020 (UTC)
- I took a stab at saying it in English. Sadly, the article uses dimension p, not n. Dicklyon (talk) 00:37, 26 August 2020 (UTC)
- "Points in R^n" is there to let the reader know that our sequence is of equal length as the dimension. — Preceding unsigned comment added by AP295 (talk • contribs) 00:01, 26 August 2020 (UTC)
The body of the article is still in need of "de-fragmentation" for lack of a better word. I don't have time to work on it now but as a general game plan, I think editors should try to make the article a bit more compact and coherent. AP295 (talk) 17:27, 28 August 2020 (UTC)
Pronumerals inconsistent between Introduction and Details sections
[edit]As at 27 Sept 2021 the introduction uses p for the number of principal components and i to index individual principal components.
The Details section uses for the number of principal components and k to index individual principal components. It uses p for the dimension of the underlying vectors and i to index individual rows in the data matrix.

To avoid creating unnecessary confusion for the first-time reader, I propose changing the Introduction to use pronumerals in the same way as in the Details section, ie replace p by and replace i by k.
I just wanted to check first whether I have misunderstood something. Please let me know if I have. Ajkirk (talk) 22:48, 26 September 2021 (UTC)
Biplots and scree plots
[edit]Please add a description in the article Biggerj1 (talk) 23:02, 8 November 2021 (UTC)
Incorrect statement in section 4 Further Considerations
[edit]The (now deleted by me) statement "Given a set of points in Euclidean space, the first principal component corresponds to a line that passes through the multidimensional mean and minimizes the sum of squares of the distances of the points from the line" is incorrect. Counterexamples are easy to find, e.g. if mean is 0. Another example is in 2d for a cloud of points with and . For this example, PCs are along and , only the one goes through the mean/ center of gravity. But is the largest component if . This example corresponds to the figure.








More generally, for an matrix with singular values, (column) mean is while first principal component is — Preceding unsigned comment added by Sunejdk (talk • contribs) 08:45, 5 December 2021 (UTC) Sunejdk (talk) 08:47, 3 December 2021 (UTC)





{kind=link}
Much too complex for most users
[edit]Sorry (and I'm actually a mathematician myself). I'd have to say all this complex mathematics is all very nice but it actually belongs in a specialist textbook, not in an encyclopaedia. A layman who wants to know what PCA is, what it does and what its limitations are is going to be completely bamboozled by this article.
I've made a start on trying to put some plain language into the article instead of all this far-too-clever mathematics - which I would move to some other strictly technical entry called maybe "Mathematics of Principal Components". Redabyss1 (talk) 07:28, 5 May 2022 (UTC)
- This logic affects all mathematical pages, which would harm Wikipedia. Wikipedia is an encyclopedia and it is used by students. One must not turn it into tutorial pages. As far as I know, people into PCA know some math (the entire concept is mathematical). But I agree that some clarity in the lede is necessary. Limit-theorem (talk) 10:19, 5 May 2022 (UTC)
- Not so. Most users pump their PCA straight out of statistical packages and have barely heard of eigenvalues or transposes.
- I have added four other major uses of PCA from the social sciences and genetics. Having done this, I see the article is too complex and meandering and reflects the input of editors with different interests and priorities. It should be broken up now into two or three articles. I don't think separating out the mathematical component would harm either mathematics or Wikipedia. Redabyss1 (talk) 07:29, 6 May 2022 (UTC)
- People have no business using PCAs if they do not know what an eigenvalue means. The concept is mathematical.Limit-theorem (talk) 10:09, 6 May 2022 (UTC)
- Though I do not agree with your proposal, to be more constructive, you should actually provide examples of how you see the topic being split. What are the two or three articles you are proposing, what content should go in each. Give a roadmap for your suggested improvements. Twotontwentyone (talk) 18:41, 23 September 2022 (UTC)
- I agree with @Limit-theorem that stripping out the math complexity is contrary to the point of Wikipedia (and constitutes a paradigm shift that would necessitate the rewriting of most Wiki pages related to math topics). Wikipedia is collection of human knowledge. Introductions or specialty sections can be used to give reads more of a bird's eye view of the topic, but the richness of information for this topic should not be watered down just because some people are not able to appreciate/use it. Twotontwentyone (talk) 18:39, 23 September 2022 (UTC)
- There is no need to strip away the math, yet at the same time the article could be much accessible to laypeople and students. The section on Intuition seems the place to provide a non-jargon laden description. That is not achieved by starting off with "PCA can be thought of as fitting a p-dimensional ellipsoid to the data". Would be great if someone could attempt a plain English version. Koedinger (talk) 00:22, 16 December 2022 (UTC)
Applications: Intelligence section doesn't belong.
[edit]This paragraph exclusively discusses factor analysis, never PCA. Why is it here? (Article already mentions FA earlier, with appropriate links.) Jmacwiki (talk) 19:26, 11 June 2022 (UTC)
Notation for the SVD uses W instead of V
[edit]In the section on how PCA relates to the SVD the SVD is described as X=U Sigma W^T, yet the page for SVD describes it as U Sigma V^T. Is there any reason as to why this page uses W instead of V? If there isn't, then it should be changed to be consistent with the main SVD page. 31.205.215.152 (talk) 00:15, 19 January 2023 (UTC)
Addition of Nature Reviews reference by 5 co-authors
[edit]I wish to add the reference to the paper Principal Component Analysis, by 6 co-authors including myself, published by Nature Reviews Methods Primers in 2022. This reference was invited by Nature Reviews and has been highly cited already. After trying to add it to this relevant Wikipedia entry with the same name, and it being repeatedly revoked as a "self citation" (to me, one of 6 co-authors including Trevor Hastie from Stanford University) and with "conflict of interest", I wish to assure the moderators that this paper is an important contribution to the subject and I am not adding the reference for any other reason. Michael.greenacre (talk) 19:56, 21 October 2024 (UTC)
- Whatever may be the case in other kinds of publications, references in Wikipedia articles should be included not because they are important contributions to their subjects, but only because they support the article text to which they are attached. Adding references to your work because you believe that it is an "important contribution", implying that you are using Wikipedia to publicise it, is not appropriate. JBW (talk) 20:21, 21 October 2024 (UTC)
- @JBW:
only because they support the article text
. Not quite. Per WP:WHYCITE "You also help users find additional information on the subject". So a reference that expands on a particular point can also be useful to add, or that provides a useful systematic review. Jheald (talk) 10:02, 22 October 2024 (UTC)
- @JBW:
- @Jheald: Well, that would be a possible reading of that sentence taken on its own, but I read it, in its context, as meaning something closer to "By citing sources in order to provide verification for article content you may also help users find more information on the subject." Links which are there only for the purpose of helping users find more information, not as citations for content of the article, belong in an external links section, not in the body of the article, presented as references; posting them as references is unhelpful, as it is likely to waste the time of readers who make the mistake of following one of them in the expectation of finding a citation for the article content to which it is attached. JBW (talk) 18:30, 22 October 2024 (UTC)
- @JBW: Per WP:EL "Links in the 'External links' section should be kept to a minimum". Also per WP:ELREG ELs are not encouraged to paywalled sites. Better therefore to place most links that provide useful additional information as citations in relevant parts of the article, to build up a bibliography in the references that is as informative and helpful to readers as possible; and to leave the EL section to just the small number of links encouraged by WP:EL. Jheald (talk) 22:46, 22 October 2024 (UTC)
- This approach of looking for little bits of policies, guidelines, "essays", etc, which one can wikilawyer about to support one's view is something most often seen from new editors, who don't yet have much experience of how Wikipedia works, so I am surprised to see it from an editor who has been here for almost 20 years. I have no intention of getting drawn into that process, but I will say just one thing about your comment above. I agree 100% with whoever it was who expressed the opinion that external links sections shod be kept to a minimum, from whom you quote. However, that means keeping external links to a minimum; it doesn't mean "building up" a large collection of external links but instead of putting them under a heading "external links" disguising them as "references" so that they don't look like external links. JBW (talk) 10:02, 23 October 2024 (UTC)
- @JBW: Per WP:EL "Links in the 'External links' section should be kept to a minimum". Also per WP:ELREG ELs are not encouraged to paywalled sites. Better therefore to place most links that provide useful additional information as citations in relevant parts of the article, to build up a bibliography in the references that is as informative and helpful to readers as possible; and to leave the EL section to just the small number of links encouraged by WP:EL. Jheald (talk) 22:46, 22 October 2024 (UTC)
Adding a highly relevant citation, of which I am one of 6 co-authors
[edit] | An impartial editor has reviewed the proposed edit(s) and asked the editor with a conflict of interest to go ahead and make the suggested changes. |
- What I think should be changed:
I have tried to add a reference to this entry 'Principal Component Analysis', it is a review paper with the same name as this Wikipedia entry, and was published in 2022. It has been reverted more than once, because I didn't understand why it was disappearing each time I tried to add it. Since I am not an experienced Wikipedia editor, I realized only afterwards that I was being accused of self-citation and conflict of interest.
- Why it should be changed:
This paper was invited by Nature Reviews for its new journal Nature Reviews Mathods Primers, aiming at introductory, yet comprehensive, descriptions of important statistical methods. I received the invitation from Nature Reviews and gathered around me 5 other international co-authors, including Trevor Hastie of Stanford University, to write this review paper. This paper is highly relevant to the Wikipedia entry, and covers similar material but includes more recent developments in some respects. I have no intention of promoting myself, only to add this reference on behalf of the 6 co-authors involved. The paper has already received hundreds of citations since publication in 2022 (433 on Google Scholar).
- References supporting the possible change (format using the "cite" button): Link to this review paper that I wish to add as a reference: https://doi.org/10.1038/s43586-022-00184-w
Michael.greenacre (talk) 13:41, 22 October 2024 (UTC)
References
- ^ GREENACRE, MICHAEL (2022). "Principal component analysis". Nature Reviews Methods Primers. 2: 100. doi:10.1038/s43586-022-00184-w.
- Worth noting that at least two of the co-authors, Patrick Groenen and Trevor Hastie, have their own wiki articles: this is indeed a top-flight set of authors.
- From the abstract this looks to be, at the very least, a good and thorough and current tutorial overview, potentially exactly the sort of thing that it may be helpful to our readers to look at. (And that we should be benchmarking our own article against, to make sure that we are indeed covering everything we may want to be.)
- @Michael.greenacre: A question, professor: is the review available on an institutional repository somewhere, or a preprint service, or any other openly accessible source? It's always helpful if citations can be available to readers who may not have university subscriptions to journals (and who don't want to get into the dark world of sites like SciHub). Jheald (talk) 15:10, 22 October 2024 (UTC)
- I'd like to add a concern here that the user appears to be involved in a certain amount of on-wiki self-promotion (for which see his user page and history of trying to install self-citations). This matter has been raised at the user's talk page and also in further discussion at the talk page of user:Belbury.
- Having looked through the COI user's edit history it seems to me that his primary (indeed almost sole) activity on Wikipedia since 2010 has been adding references to himself to the encyclopaedia. He is therefore a textbook example of a WP:SELFCITE spammer, as per the relevant policy.
- I do not see any justification for the activities of self-citing spammers to be encouraged, and if anything such users should actually be site-blocked. Therefore from my standpoint this request should be turned down without further discussion, as should any future similar requests.
- I take no view on the merits of the academic paper in question, as that does not seem to be a relevant criterion in the decision making process for such a request.
- I'd be grateful for the input of user:Belbury on this issue.
- Kind regards, Axad12 (talk) 03:55, 23 October 2024 (UTC)
- From the user's talk page, nobody had spoken to them about the COI or selfcite issues until two days ago. It's appreciated that (after what seems like an initial WP:TCHY communication issues) they were happy to declare the COI and make a talk page edit request, once they'd been made aware of the policies. In terms of encouraging others, this is the behaviour that we'd want to see from all selfciting users. The request should be judged on its own merits. Belbury (talk) 08:09, 23 October 2024 (UTC)
- I absolutely do not agree with the depressingly large numbers of editors who do what Axad12 has done here, namely accusing good-faith editors of being "spammers". Almost all of us, when we start editing Wikipedia, know little or nothing about Wikipedia's policies and guidelines, so nobody can be blamed for starting out doing things that are contrary to policies and guidelines that they don't know about; I certainly did. Continuing to do the same things after being told about the relevant policies and guidelines is a different matter, but, as Belbury has rightly pointed out, Michael Greenacre has not done that. JBW (talk) 10:11, 23 October 2024 (UTC)
- Hi,
- Thanks for your thoughts above.
- I'd just like to stress that I'm a good faith volunteer attempting to implement relevant policy as I understand it, and as such I'm more than happy to take direction on the point under discussion.
- My comments above were based upon what are, to my understanding, the relevant points of policy, namely:
- (a) WP:SPAM (WP:CITESPAM) where it states that
Variations of citation spamming include academics and scientists using their editing privileges primarily [my emphasis] to add citations to their own work
. After looking carefully through the user's contribution history I arrived at the conclusion thatprimarily
was basically the case. - And (b) WP:SELFCITE where it states that
adding numerous references to work published by yourself and none by other researchers is considered to be a form of spamming
. That also appears to be the case here, and given that any experienced academic could (if they chose to do so) easily add multiple citations to the work of academics other than themselves, it seemed that that was once again a relevant interpretation of policy (i.e. the motivation being apparently self-promotion rather than the overall improvement of the encyclopaedia). - With regard to the absolutely correct and laudable decision by the user to use the COI edit request procedure rather than editing directly themselves, my understanding was that the issue at stake was the user's apparent motivation re: trying to introduce a citation, rather than the route they adopted to do so. For example, see the warning recently posted by Belbury on the user's talk page
You may be blocked from editing without further warning the next time you use Wikipedia for promotion or advertising. Stop citing your own papers.
- As I say, I'm more than happy to take direction on the relevant policy. So, having "shown my working" and hopefully demonstrated that I'm a good faith volunteer rather than someone with an anti-academic agenda, I'd genuinely be most grateful for your further thoughts on where I've erred so that I can use that knowledge in future requests.
- Kind regards, Axad12 (talk) 13:26, 23 October 2024 (UTC)
- @Axad12: I understand everything you say, and I agree with you on every essential point. The one point on which I disagree is the use of words related to "spam", which have connotations of acting dishonestly. There certainly are people who come to Wikipedia to post downright unambiguous spam, knowing full well what they are doing. In those cases I have no compunction whatever about using the words "spam", "spammer", and "spamming", as you will be able to see if you search through my block log and deletion log. However, the substantial majority of people who post material which violates Wikipedia's policies & guidelines relating to promotion do so in good faith, genuinely not knowing that what they are doing is considered unacceptable, and I don't think calling them "spammers" is a good way of responding to their good faith mistake. That is my opinion; there are many editors who don't share it. Obviously you will have your own view of the matter, but you may like to at least consider what I have said. JBW (talk) 21:14, 23 October 2024 (UTC)
- I have just remembered something which I had virtually forgotten about, and which I didn't think of when I wrote my message above. Way back in my early days on Wikipedia, maybe round about 2007 or 2008, I suggested that we should get rid of abbreviations such as {{db-spam}} & {{uw-spam2}}. I didn't get much support, but it was in the days before I knew about Wikipedia's various noticeboards, so I just posted it on some talk page or other, where probably scarcely anyone saw it. Maybe I would have had a different response if I'd known better where to post it. Anyway, I find it interesting to now be reminded of that, and realise that, while my views on some aspects of Wikipedia have changed considerably over the years, there's one that hasn't. JBW (talk) 21:26, 23 October 2024 (UTC)
- Thanks for your comments here. I note your thoughts on the word 'spam' and whether the self-citations are done in knowledge or ignorance of the relevant policies. However, I don't really see that ignorance of the policies would mean that adding self-citation would in some way not be a problem. The policies seem to me to be quite clear in their application and I still strongly oppose allowing this user to add further self-citations.
- In fact, if I had the time I would remove their previous self-citations. Axad12 (talk) 21:50, 23 October 2024 (UTC)
- @Axad12: I am puzzled by your comment "However, I don't really see that ignorance of the policies would mean that adding self-citation would in some way not be a problem". Is there any reason to think that anyone might think that "ignorance of the policies would mean that adding self-citation would in some way not be a problem"? I find it difficult to imagine anyone holding that view. JBW (talk) 22:34, 24 October 2024 (UTC)
- I'd already removed the citations which still remained in other articles, there were only a couple in correspondence analysis and multiple correspondence analysis.
- WP:SELFCITE says to
propose the edit on the article's talk page and allow others to review it
, and the user has done this. That review will bear in mind that the proposer has a conflict of interest, but the proposer having broken some COI guidelines before being made aware of them shouldn't be a factor. Belbury (talk) 08:09, 24 October 2024 (UTC)- Agreed, but the fact that the account is used primarily for the purpose of adding self-citations (and not citations by others) is, as far as I can see, the ultimate deciding factor based on policy on whether the request should be granted or declined. Axad12 (talk) 08:14, 24 October 2024 (UTC)
- The ultimate deciding factor is whether it's a useful addition to the article. We should factor in that proposer is an author of the paper, as their view of its relevance may be not be entirely neutral. But the fact that we were very late to inform them of Wikipedia's COI guidelines doesn't tell us anything about whether the source is good or bad for the article. Belbury (talk) 08:52, 24 October 2024 (UTC)
- I disagree. Under normal circumstances the issue of whether it was useful would decide, but when it is demonstrable that the primary purpose of the account is self-citation then such a request comes under a category of behaviour which is clearly proscribed.
- As I observed above, the fact that the user was previously unaware of the policies does not have any impact on the interpretation of their apparent motivation. Axad12 (talk) 09:02, 24 October 2024 (UTC)
- By way of comparison...
- A representative of a company directly edits an article with material of promotional intent.
- The edit is reverted, they are asked to declare COI and to make the request via a COI edit request.
- They make the required declaration.
- The COI edit request is received and declined on the basis that it is of promotional intent.
- Thus, they do not get a free pass for using the COI edit request process, the deciding factor remains the motivation behind the request. Axad12 (talk) 09:08, 24 October 2024 (UTC)
- A decline would be based on the content rather than the intent. The advice at WP:COIRESPONSE is very gloomy about the kind of problems that a COI request might have, but is ultimately about vetting the edit rather than the user. Belbury (talk) 14:35, 24 October 2024 (UTC)
- If what you have said was genuinely the case then it would be open season on citation spamming because every individual edit would be (when taken on its own) okay. However, that is not the case because the activity is proscribed.
- Inevitably on subjects of this sort there must be some consideration of intent as reasonably inferred from the broader pattern. Axad12 (talk) 14:44, 24 October 2024 (UTC)
- A decline would be based on the content rather than the intent. The advice at WP:COIRESPONSE is very gloomy about the kind of problems that a COI request might have, but is ultimately about vetting the edit rather than the user. Belbury (talk) 14:35, 24 October 2024 (UTC)
- The ultimate deciding factor is whether it's a useful addition to the article. We should factor in that proposer is an author of the paper, as their view of its relevance may be not be entirely neutral. But the fact that we were very late to inform them of Wikipedia's COI guidelines doesn't tell us anything about whether the source is good or bad for the article. Belbury (talk) 08:52, 24 October 2024 (UTC)
- Agreed, but the fact that the account is used primarily for the purpose of adding self-citations (and not citations by others) is, as far as I can see, the ultimate deciding factor based on policy on whether the request should be granted or declined. Axad12 (talk) 08:14, 24 October 2024 (UTC)
- I take exception to being labelled a "a textbook example of a WP:SELFCITE spammer", after a career of almost 50 years and over 100 papers published and 10 books. Perhaps you need to check out the credentials of authors who add a citation to their own work. I wrote the first book in English on correspondence analysis in 1984, "Theory and Applications of Correspondence Analysis" (Academic Press), and so now I believe you have taken out the citations I added to my work in the entries correspondence analysis and multiple correspondence analysis. So what am I supposed to do, ask some colleague to cite them for me? It is unbelievable how much debate and wasted time this innocent act of mine has generated. The WP guidelines seem to be a bit out of touch with the academic world, where authors can be easily verified, on Google Scholar, for example. Michael.greenacre (talk) 18:05, 24 October 2024 (UTC)
- Please note that Wikipedia is not a platform for self-promotion.
- There is no need to check the credentials of users who repeatedly add citations to their own work and do that as their sole activity on Wikipedia. Such editing is a proscribed practice under the policies listed above, whether the user is Albert Einstein or a dog.
- Please do not ask a colleague to insert the relevant citations for you because that would be a breach of the policy on WP:MEATPUPPET and will result in both accounts being blocked.
- I am sorry if you are offended by the term 'self-citing spammer' but under the terms of the relevant Wikipedia policies that is what you have been on this site for the last 14 years. Repeated self-citation is deliberate self-promotion and there is no place for promotion of any kind on Wikipedia. Axad12 (talk) 18:20, 24 October 2024 (UTC)
- Thanks for your reply. Now, you clearly have not done your job on the entry "Compositional data analysis", a field I've also been working on for 25 years, since I met the founder of the method, John Aitchison. There is a group of researchers, based in Girona, Spain, who have taken over this area as if it is their own, you'll see their names: Egozcue, Pawlowsky-Glahn, Mateu-Figueras, Barcelo-Vidal, all in the same group, as well as their collaborators elsewhere, van den Boogaart and Tolosana-Delgado. You can see the citation list includes only them. Several other researchers, in Canada, Australia, UK, Czech Republic and Spain (including myself, just one of them) have taken issue with them and published many articles explaining why their approach is over-complicated and not useful for practitioners. None of our articles are cited (I have about 10, just me, as well as a book on the topic), only their articles and books (it would be interesting to see who has added all those citations to that same group's work on Wikipedia -- if anything was "group self-citing", this is). How would any of our articles, presenting a different scientific viewpoint, ever get into this entry if we didn't do it ourselves? There are some of these articles that I'm totally uninvolved in, by the Australian authors, for example, so I suppose I have a right to cite those and summarize their content? Michael.greenacre (talk) 20:00, 24 October 2024 (UTC)
- My job (to the extent that is a job, I am a volunteer) is working from the COI edit request queue, not to monitor the ongoing content of articles.
- I'd suggest you are treading rather close to the line in making accusations of the nature that you have above (that I have not done my job, that other citations were also self-citations by a rival group).
- It may be difficult for you to believe, but some people actually cite the work of others to Wikipedia and wouldn't dream of self-citing. Unfortunately your work doesn't seem to be the sort of work that other people cite.
- Your purpose of Wikipedia, it seems, continues to be solely for the purpose of self-promotion. Axad12 (talk) 20:22, 24 October 2024 (UTC)
- I again take exception to another of your statements, bordering on insulting: "Unfortunately your work doesn't seem to be the sort of work that other people cite." You should check the scientific literature and my citation rankings, very easy to obtain, before you make unfounded statements like that. You mean "... that other people cite on Wikipedia". I seem to be unable to convince you that I am not some sort of Wikipedia delinquent, after I -- naively, with no knowledge of the Wikipedia guidelines and only with good intentions -- added some highly relevant references to entries, the topics of which I know a lot about and have spent my whole scientific career studying. In the present case, I added a citation to a paper on behalf of 6 co-authors, including myself, which has unleashed this torrent of criticism and personal attack on my good faith. To tell you the truth, this gives me no appetite to spend time adding knowledge to Wikipedia, when those who are not acquainted with the subjects can operate in some type of algorithmic mode to suppress content. The usual process of peer review of scientific papers seemed tough before and sometimes disappointing, but it now seems a total pleasure to have one's work (with no restrictions on citations) considered by real experts before deciding to publish it or not, based only on scientific criteria. Michael.greenacre (talk) 23:26, 24 October 2024 (UTC)
- For the sake of clarification, I’m happy to confirm that I had meant, as you have suggested “[…] that other people cite on Wikipedia”. I meant no negative comment in relation to your stature as an academic. I’m more than happy to apologise if my comments have been construed in that way. Our general point of disagreement is (hopefully we can agree on this point!) in relation to the differences between Wikipedia policy and academic norms and – that being the case – I accept that it was remiss of me not to have been clearer.
- All of my comments throughout have related specifically to the application of Wikipedia policies, which are necessary for the running of the encyclopaedia. As I have noted above, the relevant policies relate to the extent to which an account has apparently been used for self-promotion, rather than the extent to which the user is an eminent academic (which is not a relevant consideration on Wikipedia). Axad12 (talk) 03:41, 25 October 2024 (UTC)
- I again take exception to another of your statements, bordering on insulting: "Unfortunately your work doesn't seem to be the sort of work that other people cite." You should check the scientific literature and my citation rankings, very easy to obtain, before you make unfounded statements like that. You mean "... that other people cite on Wikipedia". I seem to be unable to convince you that I am not some sort of Wikipedia delinquent, after I -- naively, with no knowledge of the Wikipedia guidelines and only with good intentions -- added some highly relevant references to entries, the topics of which I know a lot about and have spent my whole scientific career studying. In the present case, I added a citation to a paper on behalf of 6 co-authors, including myself, which has unleashed this torrent of criticism and personal attack on my good faith. To tell you the truth, this gives me no appetite to spend time adding knowledge to Wikipedia, when those who are not acquainted with the subjects can operate in some type of algorithmic mode to suppress content. The usual process of peer review of scientific papers seemed tough before and sometimes disappointing, but it now seems a total pleasure to have one's work (with no restrictions on citations) considered by real experts before deciding to publish it or not, based only on scientific criteria. Michael.greenacre (talk) 23:26, 24 October 2024 (UTC)
- Thanks for your reply. Now, you clearly have not done your job on the entry "Compositional data analysis", a field I've also been working on for 25 years, since I met the founder of the method, John Aitchison. There is a group of researchers, based in Girona, Spain, who have taken over this area as if it is their own, you'll see their names: Egozcue, Pawlowsky-Glahn, Mateu-Figueras, Barcelo-Vidal, all in the same group, as well as their collaborators elsewhere, van den Boogaart and Tolosana-Delgado. You can see the citation list includes only them. Several other researchers, in Canada, Australia, UK, Czech Republic and Spain (including myself, just one of them) have taken issue with them and published many articles explaining why their approach is over-complicated and not useful for practitioners. None of our articles are cited (I have about 10, just me, as well as a book on the topic), only their articles and books (it would be interesting to see who has added all those citations to that same group's work on Wikipedia -- if anything was "group self-citing", this is). How would any of our articles, presenting a different scientific viewpoint, ever get into this entry if we didn't do it ourselves? There are some of these articles that I'm totally uninvolved in, by the Australian authors, for example, so I suppose I have a right to cite those and summarize their content? Michael.greenacre (talk) 20:00, 24 October 2024 (UTC)
- Thanks for the question. There is indeed a preprint of this paper, which I LaTeX-formatted myself, since we hated the WORD template that Nature Reviews forced us into. I need to search for it, where it ended up. But I could certainly put it on my webpage. I also found a version on the Erasmus University website: https://pure.eur.nl/ws/portalfiles/portal/95076086/Nature_Reviews_Methods_Primer_Greenacre_et_al_2022_PCA.pdf
- I could add such links to the article if I am allowed to cite it! (incredible, the amount of discussion this simple and innocent insertion of mine has generated!) Michael.greenacre (talk) 17:55, 24 October 2024 (UTC)
- I think that an exception could be made here since the paper has 437 GS citations hence is influential. Limit-theorem (talk) 01:39, 25 October 2024 (UTC)
- SUGGESTED COMPROMISE SOLUTION
- Thanks to all for your thoughts above.
- While I still feel that published policy is on my side, I don’t wish to be seen to be unreasonable. I’m thus keen to suggest some kind of compromise solution which hopefully all contributors can agree to. With that in mind, I’d suggest something broadly along the lines of as follows:
- “The edit request to include the citation can be implemented. However, the requesting editor is advised that self-promotion is very strongly discouraged on Wikipedia and that their past editing appears to have been in breach of the policies on WP:SELFCITE and WP:CITESPAM. However, it is accepted that until very recently the contributor had been unaware of the relevant policies.
- Moving forwards, if any future similar requests are made they will be assessed solely against the contents of the relevant Wikipedia policies. The user is thus strongly encouraged to expand their contributions beyond edits specifically related to themselves, e.g. by adding citations to other academics, or by contributing to articles entirely outside of their area of academic speciality.”
- Do all parties agree that that is a fair and measured response to the present situation, recognising (I hope) the positions put forward by all contributors? Axad12 (talk) 04:09, 25 October 2024 (UTC)
- I think that an exception could be made here since the paper has 437 GS citations hence is influential. Limit-theorem (talk) 01:39, 25 October 2024 (UTC)
- Discussion flagged at WikiProject Mathematics. Jheald (talk) 10:50, 27 October 2024 (UTC)
- Add citation. I admit I haven't read through much of the above, which seems like needless nickpicking over policies. I would grant this request. It seems like a good review source for readers. Tito Omburo (talk) 13:26, 27 October 2024 (UTC)
- There sadly does not seem to be an attempt here by Michael.greenacre to make the Wikipedia article better. I am sanguine about experts who sometimes add citations to their own work while expanding or improving article content; much less so about experts who don't seem to care about the content of our article, as long as it cites theirs. The recent edits to this article are in the second category, unfortunately. --JBL (talk) 19:18, 27 October 2024 (UTC)
- In isolation, the reference in question seems fine to use. As an academic myself, I can appreciate how Wikipedia's practices can be strange and off-putting, seemingly hostile to expertise. As a Wikipedia editor, I hope that Michael.greenacre can appreciate why our "clubhouse rules", so to speak, are necessary or at least understandable. Surely it is not too hard to imagine that many people who are not noteworthy figures in their fields and who have published in far less respected venues than Nature have used Wikipedia to try and elevate their own statures. So, if we are prickly about that kind of thing, it's due to experience. I wrote a general advice page that may be relevant in this regard. Moving forward, I suggest that Michael.greenacre also point to a few other sources, written by other people, that could be inserted into this article at appropriate places. A good rule of thumb is that each paragraph should have at least one citation. That's only a rough figure, of course, but it reflects the idea that the sentences of a paragraph work together to express a concept, and each concept we cover here has to be based on a source elsewhere. In the present case, for example, § Intuition has no citations at all, which is definitely below the standard we aim for. XOR'easter (talk) 21:21, 28 October 2024 (UTC)
- There seems to be a broad consensus in favour of the 'suggested compromise solution' outlined above. I'm therefore closing down this COI edit request with the instruction that the requesting user should go ahead and make the change. He is advised, however, that any future requests (here or elsewhere) should be made using the COI edit request mechanism and that if he does not begin to contribute more widely to the encyclopaedia (beyond simple self-promotion) then it is likely that such requests will be turned down. Axad12 (talk) 10:14, 31 October 2024 (UTC)